GateKeeper Mode: Building a Quality Gate Before Letting AI Touch Your Code
Core thesis: Once AI can write code, the bottleneck is no longer “can it produce a patch?” — it’s “can the system prove that patch should be accepted?”
1. Why “AI Wrote the Code” Is Not the Hard Part
If you’ve been using AI to assist with coding for any length of time, you’ve probably run a workflow that looks something like this:
- Write a prompt, ask an agent to implement something
- Have another agent (or the same one) scan the diff for problems
- Quickly skim through the changes yourself
- Run the tests, merge if they pass
This works fine for simple tasks. But it hides several assumptions that will explode simultaneously once the scope grows.
Friendly-reviewer bias. When you ask AI to review code that AI wrote, the reviewer naturally tends to approve rather than challenge. It sees an implementation that runs, reads reasonably well, and doesn’t spontaneously ask “is this except Exception catching too much?” It has no incentive to nitpick, and no standard independent of the patch to compare against.
Tests passing ≠ behavior correct. Tests cover what tests were written to cover, not what the requirements actually demand. If your requirement is “only catch ZeroDivisionError, no over-catching allowed,” a test suite that goes 4/4 proves absolutely nothing about that constraint. Tests passing is evidence — it is not proof that every requirement is satisfied.
Missing evidence treated as acceptable. When a Critic finds no problems, it is usually interpreted as “there are no problems,” not as “there is no evidence of problems.” Those two things are not the same.
Manual review fatigue. By the time you actually want to read a diff carefully, you’ve already read through ten rounds of conversation history. Your attention is no longer on the things that matter.
Agent modified files outside the intended scope. Without an explicit boundary, an agent will happily touch files it considers “related.” Those changes sometimes don’t cause errors but quietly alter system behavior.
None of these problems exist because AI is not smart enough. They are workflow design problems. AI can already produce plausible patches. The real challenge is: do you have a system that can deterministically tell you whether a given patch should be accepted?
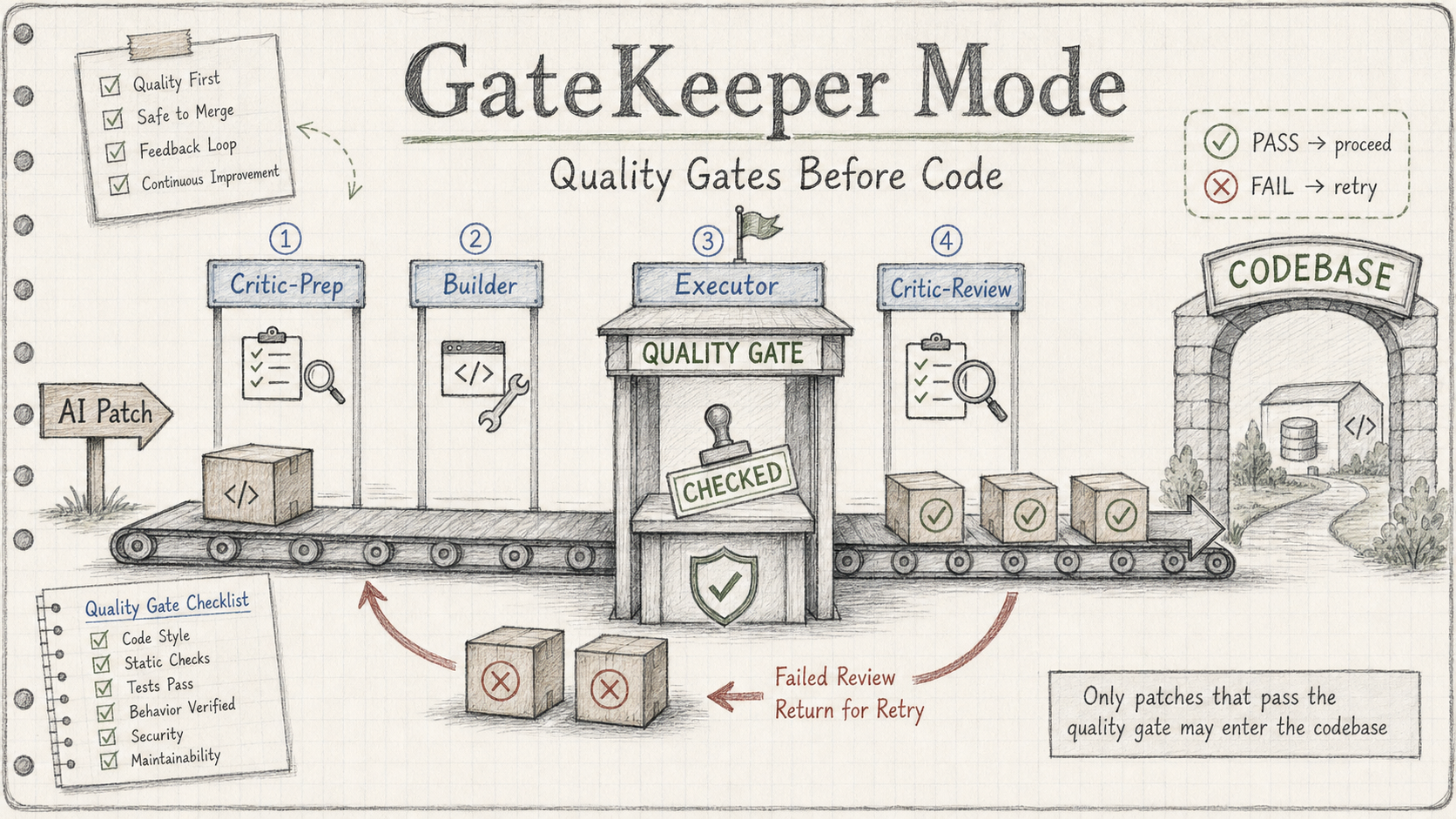
2. What a Complete Run Looks Like
Before getting into the design, let’s make clear what the actual flow looks like — as the person using it, you only need to do one thing: write a brief (task description). Everything else is script-driven.
A complete GateKeeper run, step by step:
① You write the brief
A markdown file: what to change, why, which files are allowed to be touched (allowed_files.txt).
② Critic-Prep runs first (before Builder starts)
The Critic reads the brief and writes acceptance criteria as a checklist — specific down to function signatures, edge cases, which files must not be touched. The Builder never sees this checklist.
③ Builder works in an isolated git worktree
Builder reads the brief, writes the patch, commits to an isolated branch. It has no idea what the checklist says — only what the task requires.
④ Executor runs deterministic checks
Build + unit tests + evaluator script. A non-zero exit code triggers REJECT immediately, before entering the next stage.
Where do the tests come from? Two cases:
When modifying existing code, the existing test suite is run — if the modification breaks something, it gets caught.
When adding new features, the brief requires Builder to deliver both code and tests together; the Critic checklist explicitly lists “test function must exist and pass.”
The evaluator script is a fixed set of commands written by a human in advance. Regardless of what the patch changed, it only runs those fixed commands — new tests just need to be in the same file and invoked bymain()to be executed automatically.
⑤ Critic-Review verifies each checklist item against evidence
Reads patch.diff + eval.log. Each checklist item either has direct evidence, or is marked FAILED. There is no such thing as “looks roughly right.”
⑥ Judge writes final_decision.md
APPROVE: all gates passed, patch is mergedREJECT: which gate failed, exact reason — packaged and sent back to Builder for the next round (up to 3 attempts)ESCALATE: retry limit exceeded — you receive the complete evidence package and decide the next step yourself
The only file you need to read is the last one: final_decision.md.
Here is the full workflow diagram:
flowchart TD
Task([Task brief + acceptance criteria]) --> Orchestrator{Orchestrator}
Orchestrator -->|Critic-Prep| C1[Critic<br/>reads brief + target files<br/>writes review checklist]
Orchestrator -->|Builder| B1[Builder<br/>reads brief + target files]
B1 --> B2[Builder<br/>writes patch]
B2 --> B3{Self-check: patch satisfies brief?}
B3 -->|no| B2
B3 -->|yes — commit| Exec
Exec[Executor<br/>cmake --build]
Exec --> T1{Build passes?}
T1 -->|fail| Rej
T1 -->|pass| T2[Run unit tests]
T2 --> T3{All tests pass?}
T3 -->|fail| Rej
T3 -->|pass| T4[Run semantic invariant check]
T4 --> T5{Output matches baseline?}
T5 -->|mismatch| Rej
T5 -->|matches| C2
C1 -.shared checklist.-> C2
C2[Critic-Review<br/>verifies each checklist item<br/>against patch + execution log]
C2 --> C3{Default reject:<br/>any checklist item<br/>lacks direct evidence?}
C3 -->|yes — must reject| Rej
C3 -->|no — every item has evidence| Pkg
Rej[REJECT<br/>log + Critic notes + failed gate]
Rej -->|attempt N+1<br/>max 3| B2
Rej -.->|retry limit exceeded| Esc([ESCALATE to human])
Pkg[Decision package<br/>diff + execution log + verdict]
Pkg --> Human([Human reads only final verdict])
Esc --> Human
classDef builder fill:#cfe8ff,stroke:#1f6feb,color:#000
classDef critic fill:#ffd6d6,stroke:#cf222e,color:#000
classDef gate fill:#fff3b0,stroke:#bf8700,color:#000
classDef terminal fill:#c6f6c6,stroke:#1a7f37,color:#000
class B1,B2,B3 builder
class C1,C2,C3,Rej critic
class Exec,T1,T2,T3,T4,T5 gate
class Task,Pkg,Human,Esc,Orchestrator terminal
Three roles, color-coded, with completely separated responsibilities:
| Color | Role | Objective |
|---|---|---|
| Blue | Builder | Implement the task as best it can |
| Red | Critic | Find every gap it can |
| Yellow | Executor | Replace LLM judgment with machine output |
The most critical design decision: Critic defaults to reject. A Critic that defaults to “looks fine” has no value — it is just an echo chamber. The system must place the burden of proof on the patch, not on the rejection.
3. Why Not Let One Agent Do All Three?
This question deserves its own section, because “why not just have a single Claude write and review” is something almost everyone asks.
| Responsibility | If handled by the same agent |
|---|---|
| Builder | It produces a patch optimized for “looks reasonable” |
| Critic | It is defending its own implementation |
| Executor | It reports “what the agent says happened,” not “what the machine actually measured” |
Three failure modes collapse into one: the entire loop becomes a self-confirming narrative.
The Executor must be deterministic machine output (build succeeded/failed, tests passed/failed) — not LLM judgment. This is the most fundamental difference between GateKeeper and “let AI check whether it got it right.”
4. Critic-Prep: The Key Upgrade
The earliest version (Lite) looked like this:
Builder → Executor → Critic
This is already much better than purely manual: execution results are deterministic, the Critic’s review has a log to reference, and the human only needs to read the Critic’s conclusion.
But there’s an inherent contradiction: the Critic’s evaluation standard forms only after seeing the patch. It’s very hard to be truly independent of the Builder’s implementation choices. Seeing something that “works,” it naturally approaches from “is there something wrong?” rather than “does this satisfy each pre-defined requirement?”
The full version adds Critic-Prep:
Critic-Prep → Builder → Executor → Critic-Review
Critic-Prep happens before the Builder starts. It reads the brief and the list of allowed files, and writes an acceptance checklist — precise down to function signatures, expected return values for edge cases, and which files must not be touched.
Then the Builder writes code with no knowledge that the checklist exists. This is intentional: the Builder can’t see the checklist, so its implementation won’t be guided by the checklist’s phrasing, and the Critic-Review’s judgment won’t be contaminated by the Builder’s implementation style.
The Critic is valuable precisely because it defines the evidence standard before the Builder can influence it.
5. Tool Division
This entire workflow runs locally. No framework required.
| Role | Tool | Notes |
|---|---|---|
| Builder | Claude Code (CLI) | Writes the patch, isolated in a git worktree, never sees the checklist |
| Critic-Prep | Codex (CLI) | Reads brief + allowed_files, writes acceptance checklist |
| Executor | Shell script | Build + test + evaluator, exit code decides pass/fail |
| Critic-Review | Codex (CLI) | Reads patch.diff + eval.log, verifies each checklist item against evidence |
| Judge | Shell script | Parses Critic output, writes final_decision.md, decides APPROVE / REJECT / ESCALATE |
| Human | User | Reads only final_decision.md — no need to watch every intermediate turn |
Each GateKeeper run executes in an isolated git worktree and produces: critic_checklist.md, patch.diff, eval.log, critic_review.md, final_decision.md. These files are the complete evidence chain, and the only basis for later traceability.
Why not AutoGen or LangGraph? Not because they’re bad — but before there is deterministic evidence that the workflow’s semantics are correct, introducing a framework only makes debugging harder. Get the semantics right with visible files and logs first, then consider migration.
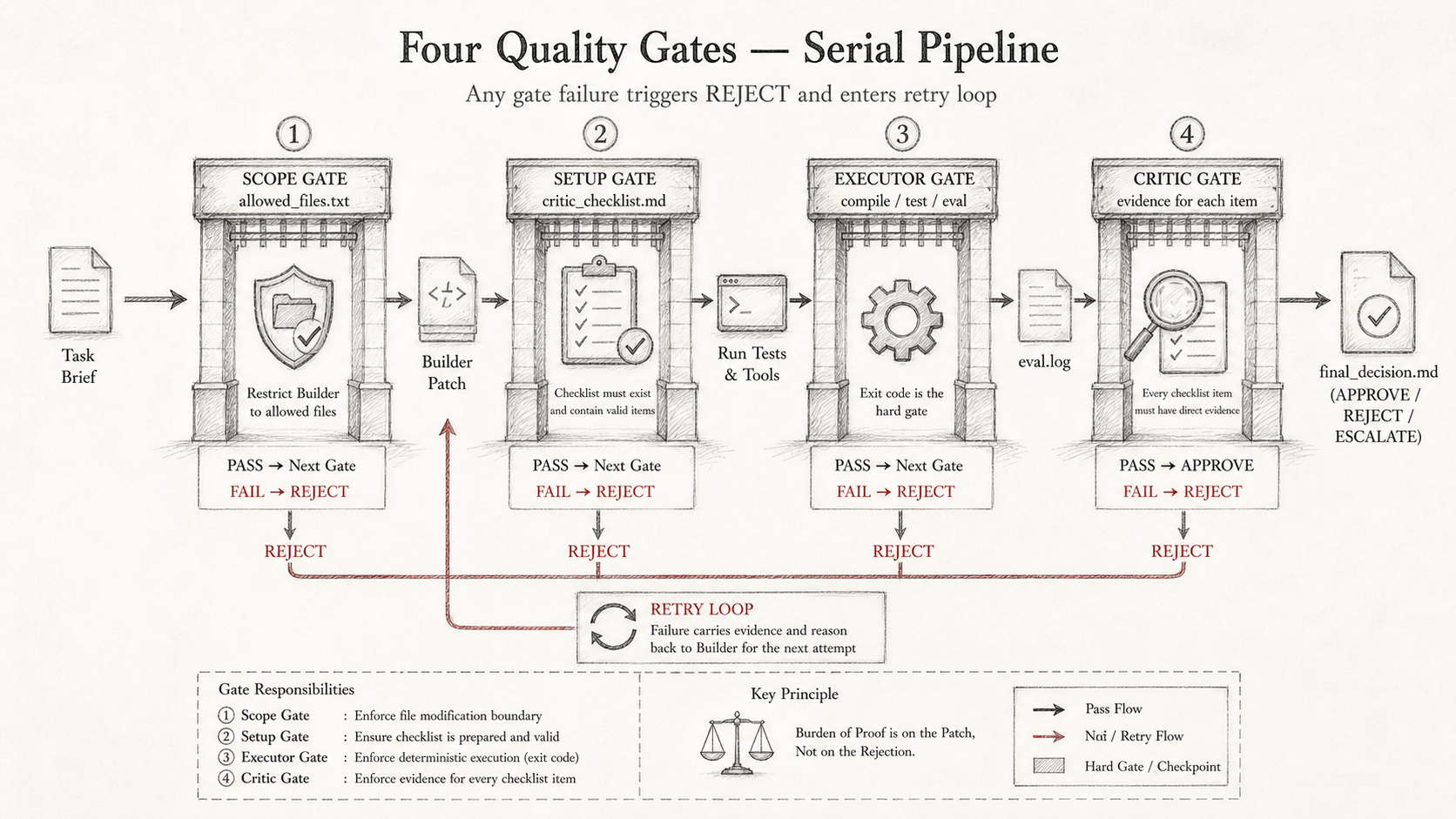
6. The Four Gates
The full pipeline has four deterministic gates. Any one of them failing triggers a REJECT:
① scope gate: allowed_files.txt constrains which files Builder can touch
Out-of-scope modifications → REJECT immediately, before Executor
② setup gate: critic_checklist.md must exist and contain valid items
If Critic-Prep didn't succeed, Builder is not allowed to start
③ executor gate: build + test + evaluator exit codes
Any non-zero exit → REJECT, enter retry
④ critic gate: each checklist item must have direct corresponding evidence
Vague "broadly satisfies" does not count; missing evidence → FAILED
The four gates are sequential. You must pass one before entering the next. The earlier a failure is found, the lower the cost.
7. Real Runs
Small examples first to validate each path, then a real C++ project. Scenarios one through four use intentionally simplified Python tasks — the goal is to make each path (one-pass, retry, ESCALATE, semantic reject) independently verifiable without introducing real-project compilation noise. Scenarios five and six are the results on a real project.
Scenario 1: One-shot Pass (APPROVE on attempt 1)
Run directory: gatekeeper_runs/20260503-173556/
Task: Write a safe_add function in python-utils/safe_add.py that handles None inputs.
Critic-Prep wrote a 10-item checklist before the Builder started:
- [ ] File python-utils/safe_add.py defines function safe_add
- [ ] Function signature is exactly safe_add(a: float | None, b: float | None) -> float
- [ ] safe_add(10.0, 2.0) returns 12.0
- [ ] safe_add(None, 2.0) returns 0.0
- [ ] safe_add(10.0, None) returns 0.0
- [ ] safe_add(None, None) returns 0.0
- [ ] safe_add(-5.0, 3.0) returns -2.0
- [ ] File python-utils/test_safe_add.py exists and includes tests for all required cases
- [ ] Evaluator script scripts/evaluators/evaluate_safe_add.sh passes in executor log
- [ ] No files outside the allowed list are modified
These 10 items cover the exact function signature, expected return values for every edge case, test file existence, evaluator pass status, and file scope constraints. There is no room for the Builder to misinterpret requirements.
final_decision.md:
Final verdict: APPROVE
Attempts used: 1 / 3
Gate: CRITIC — All checklist items have direct evidence
Attempt 1 passed directly. When the evidence standard is specific enough, a one-shot pass is not luck — it is inevitable.
Scenario 2: Deterministic Retry (RETRY → APPROVE)
Run directory: gatekeeper_runs/20260503-173731/
Task: Deliberately designed so Attempt 1 must fail (evaluator returns exit 1 on first execution), to verify that the retry mechanism itself works.
Attempt 1 eval.log tail:
Attempt number: 1
FAIL: First attempt intentionally fails to trigger retry
This is a deterministic test for retry logic.
Judge parses the EXECUTOR gate failure and triggers a retry. Builder receives the full failure evidence from Attempt 1 — including the complete eval.log and the specific checklist items that lacked evidence — and re-implements.
final_decision.md:
Final verdict: APPROVE
Attempts used: 2 / 3
Attempt 1: REJECT — Gate: EXECUTOR (exit code 1)
Attempt 2: APPROVE — Gate: CRITIC
The key design of the retry mechanism: REJECT doesn’t just return “failure” — it carries the complete evidence to the next round’s Builder. Builder sees which gate failed, what the failure reason was, and which checklist items had no evidence. That is substantially more informative than a bare “retry.” The retry’s efficiency comes from precise evidence transfer, not from the Builder guessing better.
Scenario 3: Retry Limit Exceeded (ESCALATE)
Run directory: gatekeeper_runs/20260503-173917/
Task: Both attempts fail deterministically (max_attempts=2), to validate the ESCALATE path.
final_decision.md:
Final verdict: ESCALATE
Attempts used: 2 / 2
Attempt 1: REJECT — Gate: EXECUTOR
Attempt 2: REJECT — Gate: EXECUTOR
ESCALATE is not “the process broke.” It’s the system saying: this task is beyond what can be handled automatically at this time, a human needs to look at it. final_decision.md gives the human a complete evidence chain — every round’s eval.log, Critic-Review’s item-by-item judgment, Judge’s parsing result. The human reviews the evidence package; they do not need to re-read conversation history. ESCALATE’s value is that it is a clear stopping point, not a silent failure endpoint.
Scenario 4: Semantic Reject (Tests Pass, Critic Still Rejects)
Run directory: gatekeeper_runs/20260503-153929/
This is the scenario that best illustrates the value of the Critic gate.
Task: Implement safe_divide, with the requirement that it catches only ZeroDivisionError — no over-catching.
Executor result: 4/4 tests pass.
Critic-Review judgment:
Verdict: REJECT
3. Function catches ONLY ZeroDivisionError
Evidence: FAILED — Patch shows except Exception:
6. No over-catching of unrelated exceptions
Evidence: FAILED — except Exception: catches too much
The Builder wrote except Exception, which swallows every exception — including type errors, attribute errors, and other failures that callers should know about. Tests pass because the tests only cover the normal path and the divide-by-zero path; they never touch the constraint “only catch this specific exception.”
This is the core value of Critic-Prep. It wrote “only catch a specific exception” into the checklist before seeing any code. Without that pre-written checklist, this kind of semantic problem almost always slips through review — “4/4 tests pass, code reads reasonably” — the bar for approval is too low.
This scenario also validates something more important: if you only look at the Executor gate, you’d think the patch already passed. Semantic correctness requires the Critic gate. Neither gate alone is sufficient.
Scenario 5: Real C++ Project (cpp-trader-backtester)
Run directory: gatekeeper_runs/20260503-205323/
Task: Add a volume consistency invariant test to a C++ order book implementation. Real project, real C++ compilation, Debug/ASan build.
Critic-Prep pre-wrote a 13-item checklist:
- [ ] Only cpp-trader-backtester/src/test_order_book.cpp is modified
- [ ] New function test_volume_invariant() exists
- [ ] Test records executed quantity via set_trade_callback
- [ ] Test verifies remaining resting volume after matching
- [ ] Test explicitly checks: executed_quantity + remaining_volume == total_submitted_quantity
- [ ] Build passes according to evaluate_cpp_trader.sh
- [ ] All order book tests pass
- [ ] No production files are changed
...(13 items total)
The checklist covers file scope, the test function name, three specific verification points in the test logic, build pass status, and a constraint that production files must not be touched. Every item is something that can be found as direct evidence in patch.diff or eval.log — not a single item is a subjective “broadly satisfies” judgment.
Attempt 1: REJECT — Gate: CRITIC
Missing explicit verification that executed quantity
equals expected matched quantity.
Attempt 2: APPROVE — Gate: CRITIC
All checklist items have direct evidence.
In Attempt 1, the Builder verified the remaining quantity but didn’t explicitly assert that the executed quantity equals the expected value — the invariant executed_quantity + remaining_volume == total_submitted_quantity had its right side checked but not the left. Critic-Prep’s checklist had this item explicitly, so the omission was precisely located. Attempt 2 added the missing assertion and passed.
This kind of omission is extremely easy to miss in an ordinary code review: the implementation looks complete, the tests pass, and only cross-checking against the pre-written acceptance standard item by item reveals the gap.
Git commit: b0712a6 feat(cpp-trader): Add volume consistency invariant test
Scenario 6: Stress Test ESCALATE (Exposing the Evaluator’s Own Weakness)
Run directory: gatekeeper_runs/20260503-214848/
This is the most valuable scenario in this article, and the most honest one.
Task: Fix the strategy layer’s ownership validation and fill accounting. More complex than the invariant test — involves multiple files.
final_decision.md:
Final verdict: ESCALATE
Attempts used: 3 / 3
Attempt 1: REJECT — Gate: CRITIC
Missing evidence that production strategy tests verify owned buy/sell fills.
Executor log suggests assertions were disabled.
Attempt 2: REJECT — Gate: CRITIC
Owned fill behavior is not proven; executor output shows expected position
updates did not occur while tests still reported PASS.
Attempt 3: REJECT — Gate: EXECUTOR (exit code 1)
Attempt 1’s Critic identified a critical clue:
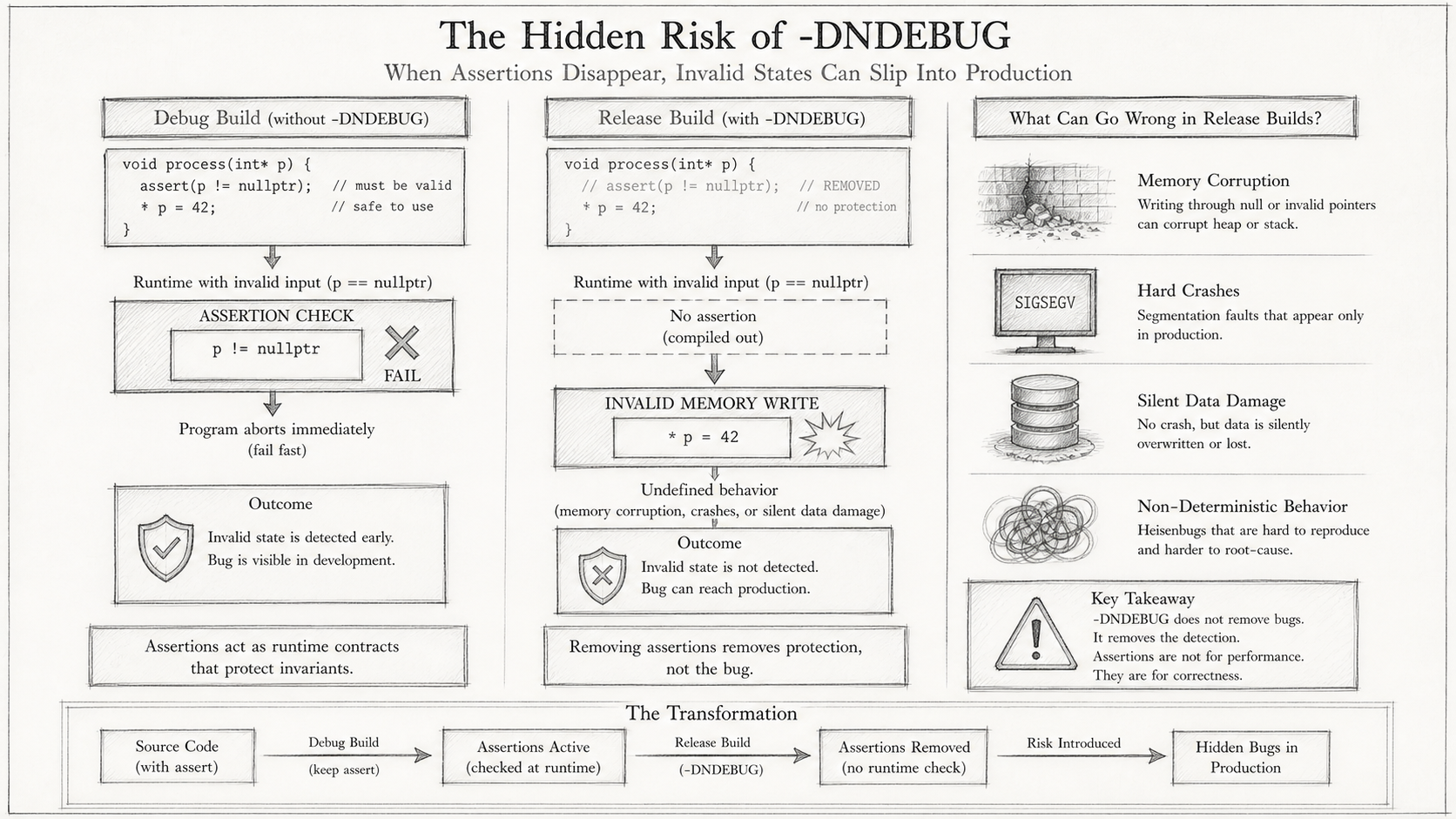
Checklist item: MomentumStrategy::on_trade ignores unrelated trades
Evidence: FAILED — executor log shows assertions were disabled via -DNDEBUG.
Tests that passed may not have actually checked the assertions.
This sentence points to the root cause.
⚠️ The evaluator had been building tests in Release mode the entire time.
The project’s Release flags include
-DNDEBUG. The C standard specifies thatassert()is preprocessed out under-DNDEBUG, becoming a no-op. Every test check that relied onassert()had not actually run — not a single line of it.Tests reported PASS because the tests had no failure paths other than
assert(). This is equivalent to deleting every assertion and running the tests: of course they all pass, but nothing was verified.The evaluator’s quality gate was, in effect, a smoke test.
The fix is straightforward: the evaluator was updated to build tests in Debug/ASan mode; the Release build is used only for benchmark smoke testing.
This ESCALATE is a valuable result, not a process failure. GateKeeper is not just a patch filter — it is a tool for debugging the quality system itself. Without the Critic insisting on evidence, the -DNDEBUG problem could have persisted indefinitely in “behavior is strange but tests are green” form. Three ESCALATEs that exposed the evaluator’s own quality issue — that outcome is worth more than any single APPROVE.
8. Callback Ordering: A Design Bug Exposed Along the Way
The strategy accounting task also surfaced a synchronous design issue unrelated to the GateKeeper workflow itself — but one that only got taken seriously because the workflow forced a close look at the evidence.
The problem is in the call ordering:
submit_order()
→ add_order()
→ match_order()
→ execute_trade()
→ trade_callback_() # Strategy::on_trade executes here
→ return order_id # too late — strategy couldn't pre-register the id
This is not a multithreaded race. It is a synchronous callback reentrancy ordering problem. When on_trade is called, submit_order() hasn’t returned yet, so the caller doesn’t have the order_id. The strategy, when it receives a fill callback, has no way to determine whether that fill belongs to an order it submitted. The bug causes no exceptions; tests pass (while assertions are disabled) — it lives as “behavior is strange but logs look normal.”
The fix is a two-phase API: prepare_order() returns the order_id synchronously first; the strategy records it, then calls submit_prepared_order() to trigger matching. Critic-Prep’s checklist required “evidence that on_trade correctly identifies its own fills” — that requirement forced the implementer to face the ordering problem head-on, with no way to route around it.
9. What This Doesn’t Solve Yet
It is not a stronger-prompt technique. GateKeeper Mode changes workflow structure, not the quality of a single conversation. If your task requires a smarter agent, this system doesn’t solve that problem.
It cannot replace domain tests. GateKeeper ensures the items in the checklist have evidence — but checklist quality depends on the quality of Critic-Prep’s input. If the brief is incomplete, the checklist won’t cover all requirements. The evaluator can only guarantee what it tests.
It cannot prove an agent is always correct. A passing patch is “a patch accepted under the current checklist and test coverage” — it is not “an eternally correct patch.” These two things are different and should not be conflated.
The Attacker role is not yet wired in. The full design would have an Attacker role, before Critic-Review, that actively tries to break the patch with boundary inputs and passes its results as additional evidence to the Critic. The current quality gates are all defensive — none are actively adversarial.
And the most important of all:
An Executor gate is only as strong as the commands it runs. If tests depend on
assert(), running them under-DNDEBUGturns the quality gate into a smoke test.
This is not a GateKeeper problem — it is the user’s responsibility. GateKeeper’s value is in making that weakness visible. But fixing it requires the user to act.
10. Why This Matters for Agent-Assisted Optimization
If you want an agent to help with performance optimization — reduce memory allocations, optimize hot paths, adjust data structure layouts — you need to confirm one thing first: do you have the ability to prove that the code’s behavior after the optimization is consistent with before?
Performance optimization is, at its core, changing the implementation without changing the semantics. If your correctness gates are still fuzzy, test results passing after an optimization only tell you “it runs” — they don’t tell you “the semantics didn’t change.” You’re likely to end up with a version that runs faster but whose behavior has quietly shifted, and tracing which step introduced the problem becomes very difficult.
Before correctness and evidence gates are in place, you should not let an agent do performance optimization.
This is the subject of Blog 2. The infrastructure GateKeeper Mode provides — deterministic scope gate, independent Critic-Prep, evidence-backed checklist, Debug/ASan Executor — is the prerequisite for letting an agent safely perform performance optimization. Get the correctness proof right, and performance optimization becomes meaningful. Skip this step, and you’re building on a foundation that doesn’t exist.
If You Want to Try This
The scripts, brief templates, and complete run records for all six scenarios are in the gatekeeper_runs/ directory (each subdirectory is named by run timestamp, with the full artifact chain preserved). Each run directory contains the complete evidence chain from brief to final verdict: critic_checklist.md → patch.diff → eval.log → critic_review.md → final_decision.md.
Start with a small task where you already have tests: write a brief, let Critic-Prep generate the checklist, then let Builder work — but before reading the Builder’s implementation, read the checklist first. That ordering itself will let you feel the difference between “evidence standard precedes the patch” and “reviewing after the patch already exists.”
cpp-trader-backtester is a sandbox project used to validate the workflow — not an HFT production system. All run results shown in this article come from real executions, including the ESCALATE that exposed the -DNDEBUG problem. That ESCALATE is the most valuable result in this article, not the worst one.